A common question we get from customers is “how does Kogni discover sensitive information?”
In this post, we will describe how Kogni discovers sensitive information in the following three types of data:
- Structured Data: database tables, CSV files
- Unstructured Text Data: varchar/clob columns, log files
- Images: scanned documents, facial images, fingerprints
(1) Structured Data
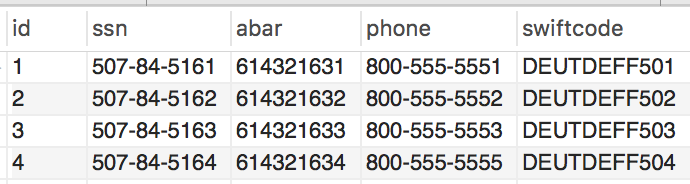
For tabular structured data, for each column, Kogni considers the following signals to make a probabilistic estimate of what (if any) sensitive type the column contains:
- Column name
- In enterprise databases, columns often have meaningful names (e.g., soc#, card_nr). Therefore, Kogni leverages column name information as one of the signals to determine what sensitive type the column might contain.
- Does the column data match the pattern of a known sensitive type?
- Examples
- SSN has 9 digits often formatted as ddd-dd-dddd.
- US bank account number has 8-17 digits.
- Kogni has a pattern library spanning a diverse set of sensitive types such as SSN, credit card, US bank account number, email, IP address, etc.
- Does the column data pass the checksum test (if available)?
- Many sensitive types have a checksum test that can be used for validation.
- Luhn algorithm can be used to validate several identification numbers, such as credit card numbers, ABA Routing Numbers, US National Provider Identifier numbers, Canadian Social Insurance Numbers, etc.
- Does the column data match the fingerprint of a known sensitive type?
- Kogni allows authorized users to manually flag columns. Behind the scenes, Kogni computes the fingerprint of that column’s data. The fingerprint captures the distinguishing characteristics of the column’s data.
- As an example, let’s say an authorized user flags the employee table’s soc# column as SSN. If a column in another database matches the SSN fingerprint, it will also get flagged as SSN.
- Does the column data have high identifiability?
- Identifiability measures how uniquely a given value identifies a certain entity (e.g., a person).
- Two extreme examples for illustration:
- A table has two columns: student_SSN and passport_number. Typically, a given value of passport_number will map to a single value of student_SSN. Consequently, Kogni will learn that passport_number column has HIGH identifiability.
- Another table has two columns: student_SSN and is_on_financial_aid (true/false). Therefore, a given value of is_on_financial_aid will map to many different values of student_SSN. Consequently, Kogni will learn that is_on_financial_aid column has LOW identifiability.
(2) Unstructured Text Data

Kogni discovers sensitive information in unstructured text data such as varchar/clob columns or log files. Many of the techniques for structured data are also applicable to unstructured data. There are two additional techniques for unstructured data:
- Context
- When deciding if a word/phrase contains sensitive information, Kogni looks at the neighboring words for cues.
- Given enough labeled data, Kogni uses machine learning techniques such as Recurrent Neural Networks to detect sensitive information in unstructured text data.
(3) Images

Detecting sensitive data in images is critical for two reasons:
- Certain images types, such as facial images and fingerprints, are HIPAA protected identifiers.
- Data breaches are not limited to text data. Here is an example of a recent high-profile data breach involving image data:
- "FedEx was storing more than 100,000 scanned documents including passports, drivers licenses, and security IDs on an unsecured Amazon S3 server. This Amazon S3 server was forgotten in an years-old acquisition."
Kogni detects sensitive data in images using two methods:
- Image Classification and Object Detection
- These techniques are used to check (1) if an image is a scan/copy of a driver’s license, US passport, credit card, etc. and (2) if an image contains a full face photograph.
- For image classification, Kogni uses an ensemble of ResNeXt models. Kogni leverages pre-trained models and harnesses transfer learning to achieve near-perfect accuracy even when only a small quantity of images is available for training the models.
- OCR followed by sensitive data discovery
- This technique is helpful for scanned copies of documents containing sensitive data such as SSN, credit card number, etc.
- Kogni first runs OCR to extract text from the image, and then feeds the extracted text to its standard sensitive data discovery algorithms.
Conclusion
We described how Kogni discovers sensitive information in structured data, unstructured text data, and images. With the rapidly rising volume, variety, and velocity of data, automatic sensitive data discovery is almost a must-have for today’s dynamic IT organizations. Kogni, with its support for a broad range of data sources, data formats, and sensitive types, is the ideal solution to this problem.
To see Kogni in action: Request Demo
