Why Automated Sensitive Data Catalog
A common misconception is that IT teams can manually compile a list of sensitive data

Many of the recent data breaches were detected too late. Consider Equifax data breach:
Question: How can sensitive data such as Social Security numbers and credit card numbers be accessed at such a massive scale without raising alerts to Equifax security team?
Next Question: If sensitive data such as Social Security numbers and and credit card numbers were accessed in an unusual way in your organization, do you have monitoring in place to generate alerts?
Unfortunately, for most organizations, the answer is no.
With the growing number, variety, and locations of data stores, most organizations do not have a firm grip on where their sensitive data is located, let alone monitor those sensitive data locations for suspicious access.
In this post, we describe how to build a system to continuously monitor for suspicious sensitive data access.
Three components are needed to build such a monitoring system:
Next, let’s zoom into each of three components.
Consider the recent FedEx data breach:
Do you know if you are storing sensitive data in S3?
With the growing adoption of cloud and big data, a typical organization has far too many data stores to manually examine and compile a list of sensitive data locations. Clearly, sensitive data discovery needs to be automated.
Relevant Read: Why Automated Sensitive Data Catalog
The Kogni Discovery Engine is the ideal solution for this problem. It scans an enterprise’s data stores and automatically builds a Sensitive Data Catalog. The Sensitive Data Catalog can be explored in Kogni’s intuitive, interactive dashboard, and it can also be accessed through an API to build higher-level functionality such as monitoring for suspicious sensitive data access.
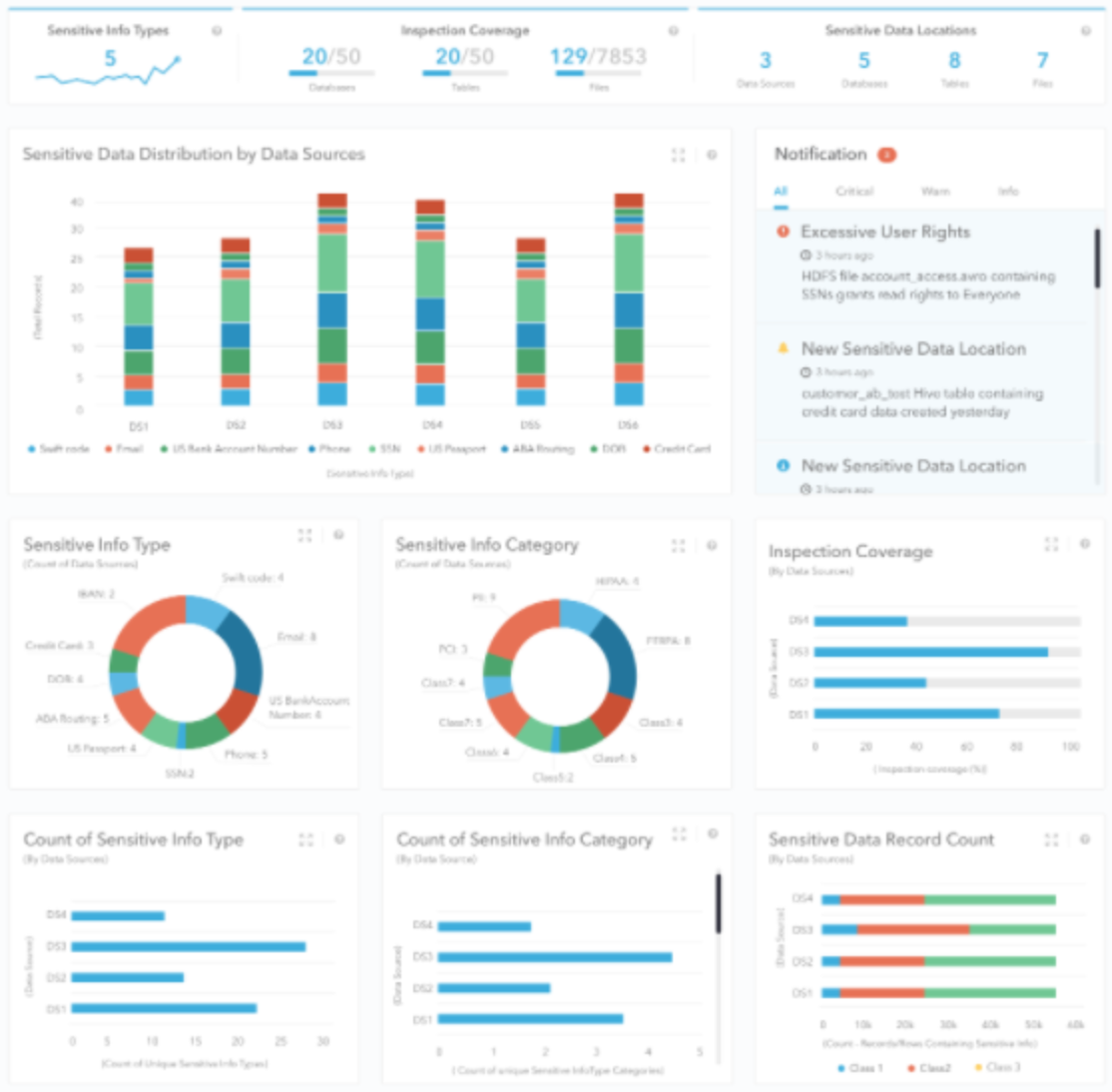 Kogni’s Interactive Sensitive Data Dashboard
Kogni’s Interactive Sensitive Data Dashboard
With the Sensitive Data Catalog in place, we now know the sensitive data locations. However, in order to monitor for suspicious sensitive data access, we need to know who is accessing sensitive data, when, from where, using what API…
We need audit logs.
An audit log records events containing information about who accessed what, when, from where, etc. Audit events from various audit logs are typically streamed into Kafka. The Anomaly Detection Engine reads directly from Kafka, and is decoupled from raw audit logs.
Good news: Almost all data stores (Oracle, MySQL, S3, Hadoop, etc.) support audit logs.
Bad news: Each audit log has its own custom format.
What’s needed is a Message Translator that translates these custom audit-event formats into a Canonical Data Model which our downstream Anomaly Detection Engine understands.
Additionally, audit logs only tell us what tables or files were accessed. By themselves, audit logs do not tell us what sensitive data, if any, was accessed. This is where the Sensitive Data Catalog is leveraged. Kogni has a Content Enricher that queries the Sensitive Data Catalog with the name of the table/file in the audit event, and enriches the message with the information about what, if any, sensitive data was accessed.
Here is a pictorial representation of the entire pipeline:
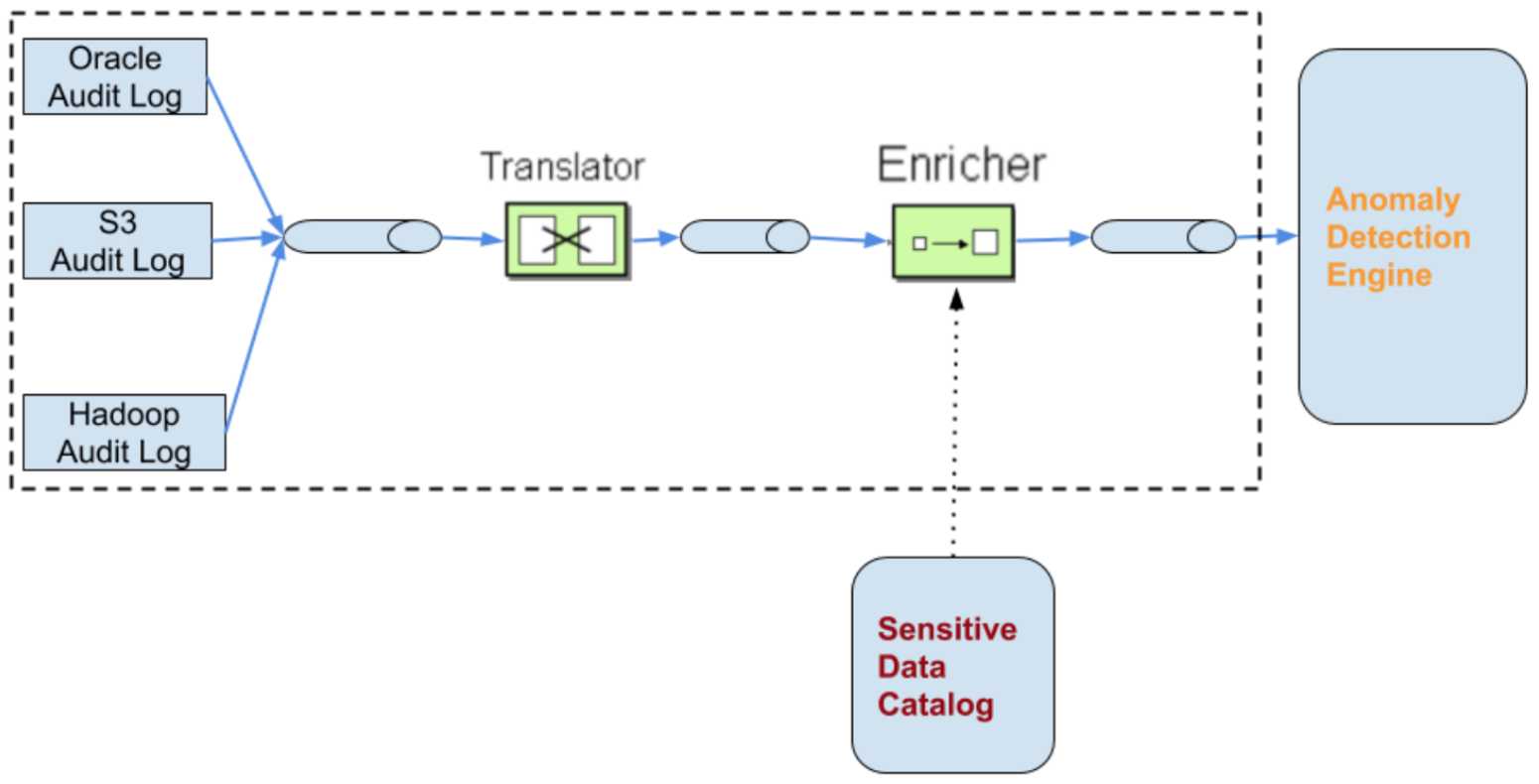
With the first two components (Sensitive Data Catalog and Audit Log Ingestion) in place, every time a piece of sensitive data is accessed anywhere in the enterprise, a canonical audit event will be generated capturing what sensitive data element was accessed, when, by whom, from where, using what API, …
This audit event stream is fed into an Anomaly Detection Engine to detect and alert on anomalies.
Here are examples of anomalies we would like the Anomaly Detection Engine to detect:
A visual examination of the time-series plot of a user’s sensitive data access counts can reveal many of these anomalies:
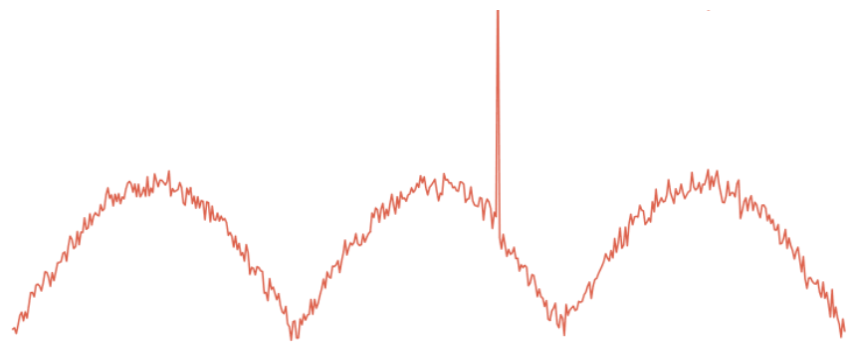
But given the high number of users and multitude of sensitive information types, it is infeasible to check for anomalies visually and manually. The anomaly detection process needs to be automated. We need an anomaly detection model that can automatically learn what is normal, and alert on abnormal/unusual/suspcicious behavior.
Moreover, the anomaly detection model needs to handle the following:
One will need to define too many rules to handle the above objectives. Worse, these rules will need to be modified frequently to adapt to future changes.
Therefore, we decided to build machine-learning based anomaly detection models so that the models can self-learn from historical data and adapt to future changes.
Thankfully, there is vast research done in this field. Here are a few selected ones that we have found useful:
We discussed why it is imperative to monitor sensitive data activity and described the concrete steps required to build such a monitoring system. We also discussed the need for Automated Sensitive Data Catalog and how it can be leveraged for detecting suspicious access of sensitive data.
Interested in learning more about Kogni’s sensitive data activity monitoring? Request Demo