Why Automated Sensitive Data Catalog
A common misconception is that IT teams can manually compile a list of sensitive data

The General Data Protection Regulation (GDPR) is a regulation intended to strengthen data protection for all individuals within the European Union. It becomes enforceable from May 25, 2018.
One of the key requirements of the GDPR is the right to erasure. The right to erasure provides individuals the right to request erasure of personal data related to them.
As a result, enterprises are confronted with a hard deadline of May 25, 2018 before which they must implement the right to erasure across all their enterprise data stores. However, many enterprises lack the technology to identify the data stores containing an individual’s personal data, making it impossible to erase an individual’s personal data when requested by the individual.
There are two technical problems that need to be solved to support the right to erasure:
Let’s tackle the two problems one by one.
A common misconception is that IT teams can manually compile a list of sensitive data locations. However, manual sensitive data discovery is impractical for the following reasons:
The sheer number of data stores potentially containing sensitive data makes manual discovery impractical. Clearly, automation is needed.
Combine the fact that in today’s dynamic IT environment, sensitive data locations keep changing with time, automatic sensitive data discovery becomes almost a must-have.
The Kogni Discovery Engine is the ideal solution to this problem. It scans an enterprise’s data stores and automatically builds a sensitive data catalog. The sensitive data catalog can be explored in Kogni’s intuitive, interactive dashboard, and it can also be accessed through an API to build higher-level functionality such as data-erasure logic.
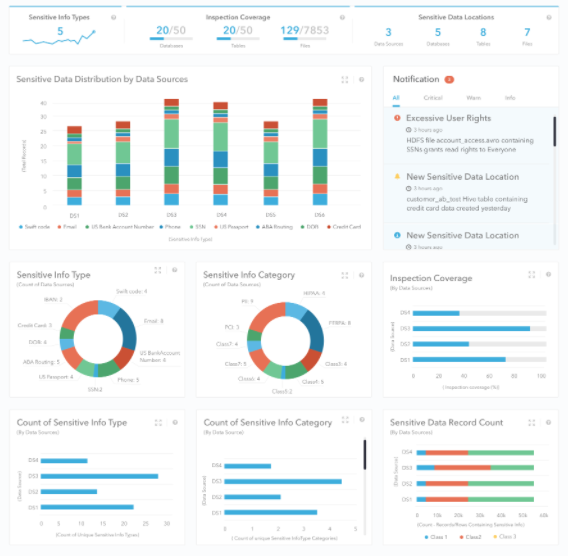 Kogni’s Interactive Sensitive Data Dashboard
Kogni’s Interactive Sensitive Data Dashboard
Highlights of the Kogni Discovery Engine:
Because of Hadoop’s largely immutable files, erasure requests are best supported using the Command Pattern. When individuals request erasure of their personal data, create and store command objects encapsulating all information needed to execute the commands later. Periodically, a batch job picks up all the pending commands and executes them by following three high level steps:
Of course, implementing these high level steps is highly dependent on enterprise-specific business logic. Kogni offers pre-built, flexible workflows that can be rapidly tailored to capture enterprise-specific data-erasure business logic.
Enterprises can accelerate their GDPR compliance journey by leveraging automated sensitive data discovery tools. Kogni, with its automated sensitive data discovery engine and customizable data-erasure workflows, is an invaluable aid in implementing the right to erasure.
Learn how Kogni can help your enterprise with GDPR compliance: Request Demo