Why Automated Sensitive Data Catalog
A common misconception is that IT teams can manually compile a list of sensitive data

Over the years, the size of the data being stored by the organizations has been growing exponentially. This has increased concerns over the data privacy. With the threat of data breaches, organizations face the challenge of protecting users sensitive information including Phone Numbers, Emails etc. Also, the organizations need to stay in compliance with International regulations. With the ever-increasing data regulations and their complexity, it would be a daunting task for the organizations.
Kogni is a unique tool which does not only redact sensitive information but also discovers all the places they are stored. It uses Machine Learning to leverage Data Security and ensures that the organizations stay in compliance with industry guidelines and international regulations like NIST, GDPR, PCI etc.
Due to sheer volumes of data being stored, it is very difficult for the organizations to monitor all of the data. Kogni discovers all the places where the sensitive information is stored. A very useful feature of it can be to monitor the places where the sensitive information is stored and thereby adding an extra layer of security to all the sensitive data.
In this blog, we present a method to monitor sensitive data. We compare different methods of achieving this and advantages of one over the other.
Approach: One plausible way of detecting the security breaches can be monitoring all the user actions which are accessing sensitive data. This can be done by analyzing various Audit logs. By detecting anomalies in these logs, we can detect security breaches on private data.
There are several audit logs that are generated by various processes within the Hadoop environment. Some processes generating audit logs:
Cloudera Navigator Audit logs: Cloudera Navigator provides a unified auditing service for all the major services(see all the services supported by Cloudera Navigator Auditing service here). A big catch is that if we solely rely on it, it imposes an extra infrastructural requirement to run the Anomaly Detection. Therefore, we will not solely rely on it but we will use it to improve our pipeline.
Advantages:
Disadvantages:
Sample Cloudera Navigator Audit log:
{
"timestamp" : "2018-02-05T23:40:59.000Z",
"service" : "CD-IMPALA-SpjIIzkY",
"username" : "root",
"ipAddress" : "10.0.0.58",
"command" : "CREATE_TABLE",
"resource" : "test:test3",
"operationText" : "create table test3(id int, phone String)",
"allowed" : true,
"serviceValues" : {
"operation_text" : "create table test3(id int, phone String)",
"database_name" : "test",
"query_id" : "204880ee6fccc9e8:9502f66e00000000",
"object_type" : "TABLE",
"session_id" : "374a675274aa2524:eba8aa57e61ca69a",
"privilege" : "CREATE",
"table_name" : "test3",
"status" : ""
}
}
HDFS Audit logs: HDFS audit logs records every file access on HDFS. Many of the relational databases are stored in files on HDFS. So, every related audit log related to the files will be logged.
Advantages:
Disadvantages:
Sample HDFS Audit log:
{
“allowed”: true,
“serviceName”: “hdfs”,
“username”: “centos”,
“src”: “/user/centos”,
“eventTime”: 1512538718000,
“ipAddress”: “10.0.15.3”,
“operation”: “listStatus”,
“dest”: null,
“permissions”: null,
“impersonator”: null,
“delegationTokenId”: null
}
Impala Audit logs:
Impala audit logs are generated on every node where the Impala daemon is running.
Advantages:
Disadvantages:
Sample Impala Audit log:
{
"1518626522508":{
"query_id":"51488b4f90313d18:2860e81700000000",
"session_id":"b4fd37e314dd6a6:c822b00988ff0086",
"start_time":"2018-02-14 16:42:02.475475000",
"authorization_failure":false,
"status":"",
"user":"root",
"impersonator":null,
"statement_type":"CREATE_TABLE",
"network_address":"10.0.0.58:36646",
"sql_statement":"create table test5 (name String)",
"catalog_objects":[
{
"name":"test.test5",
"object_type":"TABLE",
"privilege":"CREATE"
}
]
}
}
Hive Audit logs:
Hive uses Hive metastore for service logging. Hive Audit logs are stored with the class name org.apache.hadoop.hive.metastore.HiveMetaStore.audit. These needs to be filtered out before processing further.
Advantages:
Disadvantages:
Sample Hive Audit log:
2017-12-05 05:10:56,239 INFO org.apache.hadoop.hive.metastore.HiveMetaStore.audit: [pool-5-thread-1]: ugi=hue/ip-10-0-15-3.us-west-2.compute.internal@CLAIRVOYANT ip=/10.0.15.3 cmd=get_functions: db=cloudera_manager_metastore_canary_test_db_hive_hivemetastore_6b039170b5491248c0b846d658d38e58 pat=*
Some factors affecting Audit logs: We considered some common factors that may effect the Audit logs.
Kerberos: Kerberos is a network authentication protocol which gives certain access to certain people based on Principal they belong to by generating tokens valid for a certain time.
Here we perform a detailed comparison of how the resulting Audit logs are affected when Kerberos is installed and when not installed.
HDFS Audit logs on Non-kerborized cluster:
{
“allowed”: true,
“serviceName”: “hdfs”,
“username”: “centos”,
“src”: “/user/centos”,
“eventTime”: 1512538718000,
“ipAddress”: “10.0.15.3”,
“operation”: “listStatus”,
“dest”: null,
“permissions”: null,
“impersonator”: null,
“delegationTokenId”: null
}
HDFS Audit logs on Kerborized Cluster:
{
“allowed”: true,
“serviceName”: “hdfs”,
“username”: “centos@CLAIRVOYANT”,
“src”: “/user/centos”,
“eventTime”: 1512429082151,
“ipAddress”: “10.0.15.3”,
“operation”: “listStatus”,
“dest”: null,
“permissions”: null,
“impersonator”: null,
“delegationTokenId”: null
}
Hive on Non-Kerborized Cluster:
2017–11–30 17:33:50,912 INFO org.apache.hadoop.hive.metastore.HiveMetaStore.audit: [pool-5-thread-21]: ugi=centos ip=10.0.15.3 cmd=source:10.0.15.3 get_table : db=test tbl=movies
Hive on Kerborized Cluster:
2017–12–05 04:52:32,209 INFO org.apache.hadoop.hive.metastore.HiveMetaStore.audit: [pool-5-thread-21]: ugi=centos@CLAIRVOYANT ip=10.0.15.3 cmd=source:10.0.15.3 get_table : db=test tbl=movies
Impala Audit logs on Non-kerborized Cluster:
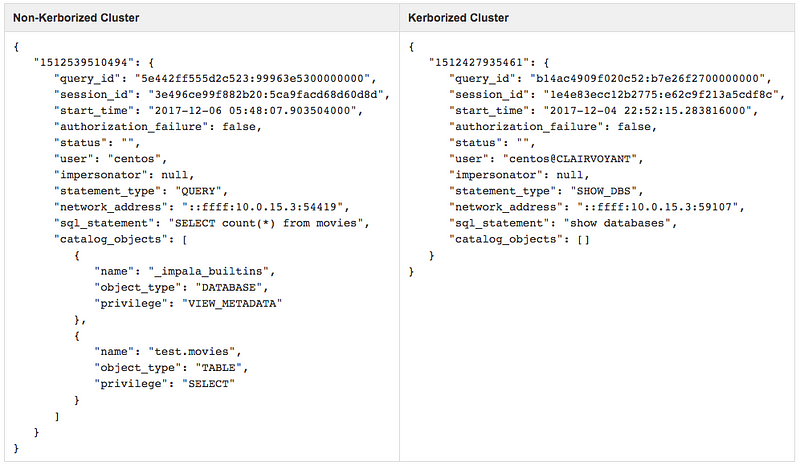
Effect of Kerberos: The User field is being affected after installing Kerberos. On Kerberos cluster, the username field also contains the principal to which the user belongs.
Connection Types: Different types of connections for a service also affecting the Auditing logs. For example, Hive can be accessed through Hue, HiveCLI, and Beeline. Similarly other services.
HDFS Audit log accessed from Hadoop FsShell:
{
"allowed": true,
"serviceName": "hdfs",
"username": "centos",
"src": "/user/centos",
"eventTime": 1512538718000,
"ipAddress": "10.0.15.3",
"operation": "listStatus",
"dest": null,
"permissions": null,
"impersonator": null,
"delegationTokenId": null
}
HDFS Audit log accessed from Hue:
{
"allowed": true,
"serviceName": "hdfs",
"username": "centos",
"src": "/user/centos",
"eventTime": 1512538602501,
"ipAddress": "10.0.15.3",
"operation": "listStatus",
"dest": null,
"permissions": null,
"impersonator": "hue",
"delegationTokenId": null
}
Effect of Connections: For many services, the impersonator field seems to be effected. Similarly, we have performed various experiments for JDBC connections etc.
Analyzing and Comparing various Audit logs:
As we discussed above, there are various processes within the Big Data environment generating Audit logs. Here we analyze and compare them for simple queries.
Audit logs for Impala:
Query: “show databases”
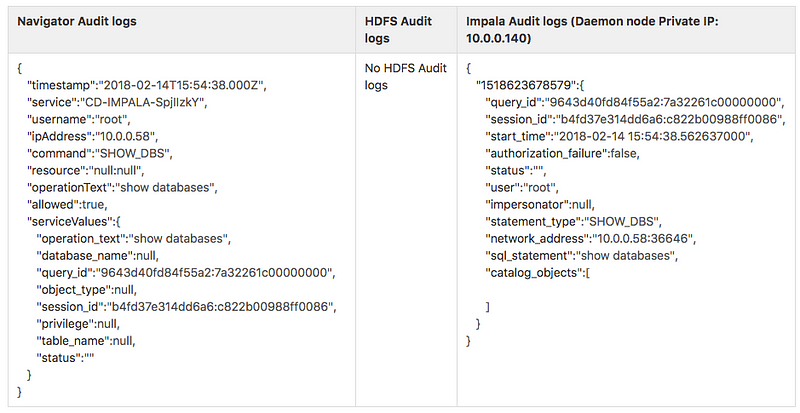
There are no related HDFS Audit logs. This can be one of the scenarios where there is data access regardless of accessing files on HDFS.
Query: “select * from test2”. Reading the content from test2 table in test database.
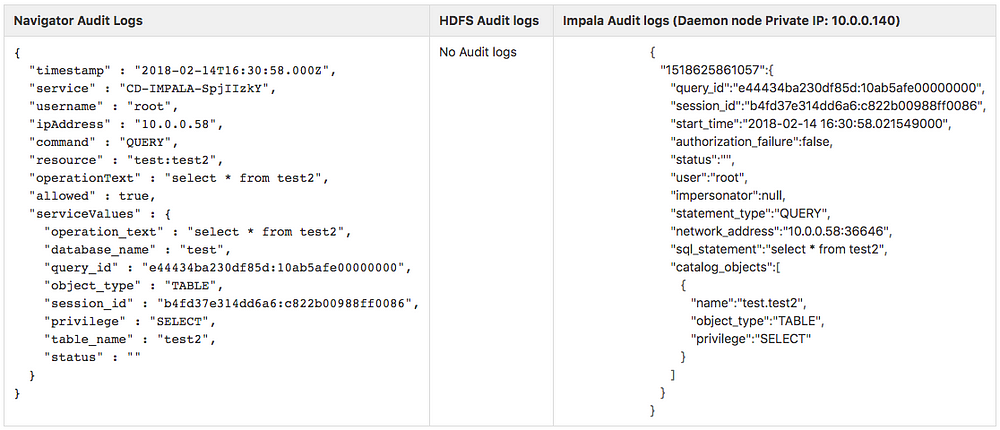
Here, we analyze more into the Audit logs and compare some of them.
Query: “create table test5 (name String)”
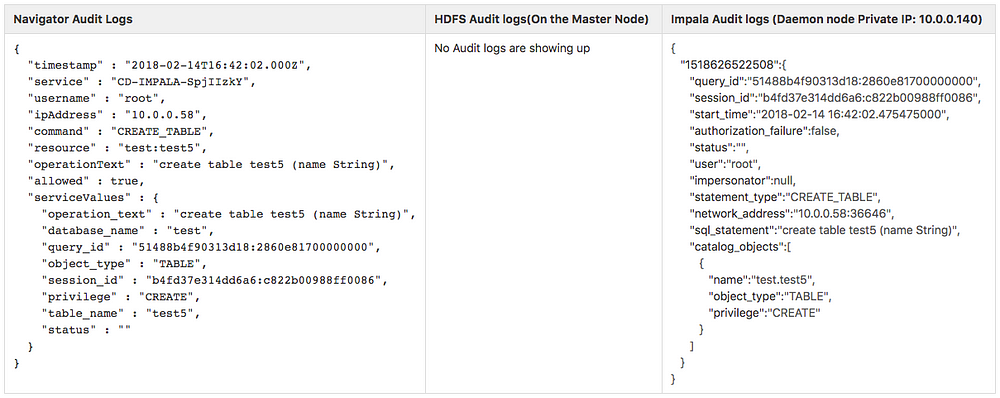
After executing and analyzing simple Impala queries (typically involving one or no tables), it is found that Navigator and Impala Queries are similarly structured giving almost the same information.
Navigator has a “service” field which can be used to filter out the logs while Impala Audit logs don’t have to be filtered.
The Query that was being executed was accessed through “operationText” field in Navigator logs while using “sql_statement” in Impala Audit logs.
Let’s do the same comparison for a little more complex queries like joins, where multiple tables are involved.
Query: “select t1.id, t1.name, t1.email, t2.phone from test4 t1 join test3 t2 on t1.id = t2.id”
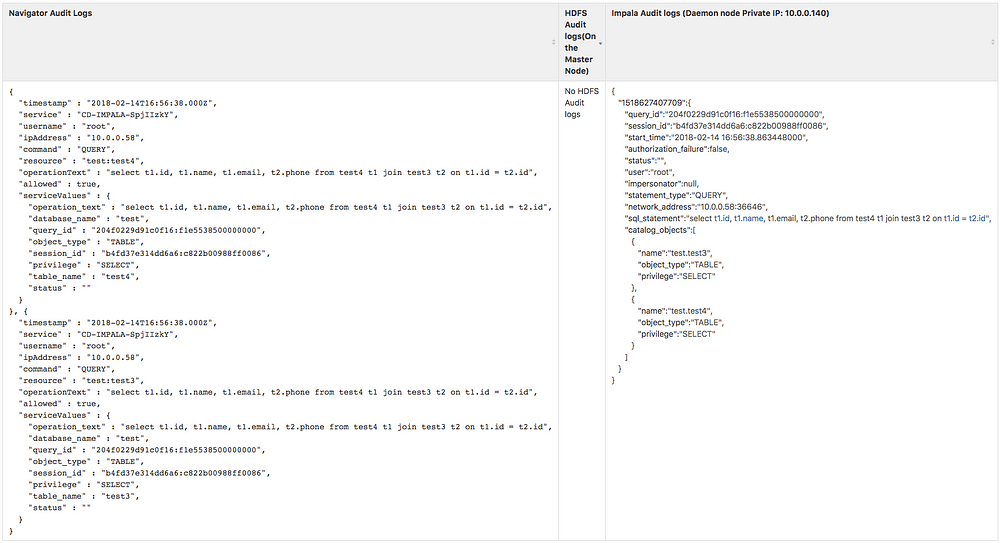
Though Impala Audit logs offer more information like port address, for our case currently we are not considering the port addresses in order to ease the development process.
Also, the multiple audit logs for each query is stored under one JSON object in Impala logs while Navigator produces multiple records. Similarly, multiple audit logs are produced for cases like invalidating metadata, other joins or cases where we are accessing multiple tables.
Upcoming:
In this blog, we discussed the need and advantages of adding an extra layer of security for the sensitive data. We also discussed various Audit logs and effect of Kerberos on them.
In my next blog, we will be discussing Hive Audit logs, Pipeline of the Anomaly Detection, using Kogni API to identify sensitive information and method to identify the Anomalies.